BBYET-141 Solved Assignment
- Describe the structure of a eukaryotic cell with a properly labeled diagram.
- Discuss ‘Operon Concept’. Describe its structure and role in gene regulation.
- a) Describe the double helix model of DNA with a neat, well-labelled diagram.
b) How is the organization of DNA in prokaryotes different from that of eukaryotes? Discuss. - a) What is Nucleosome? Explain its structure with the help of a suitable diagram.
b) Discuss the main features of the genetic code. - a) Enlist the major differences between plant and animal cells.
b) Explain Chargaff’s Rule. - Describe the structure, composition and functions of mitochondria along with a well-labelled diagram.
- Describe Griffith’s experiment for the demonstration of DNA as a genetic material with a properly labelled diagram.
- Describe various stages of Meiosis I with the help of a well-labelled diagram.
- List various models proposed for the structure of cell membranes. Explain the ‘Fluid Mosaic Model’ with the help of a well-labelled diagram.
- Write short notes on the following:
i) Golgi apparatus
ii) Function of the cell wall in plants
iii) Cloverleaf model of t-RNA
iv) Enzyme telomerase
Answer:
Question:-1
Describe the structure of a eukaryotic cell with a properly labeled diagram.
Answer:
Structure of a Eukaryotic Cell:
A eukaryotic cell, found in plants, animals, fungi, and protists, is a complex, membrane-bound structure with specialized organelles performing distinct functions.
- Nucleus: The control center containing DNA, enclosed by a double membrane with nuclear pores. It regulates gene expression and cell division (e.g., in animal cells).
- Cell Membrane: A phospholipid bilayer with proteins, controlling entry and exit of substances, maintaining cell integrity.
- Cytoplasm: The jelly-like matrix hosting organelles, facilitating metabolic reactions.
- Mitochondria: Double-membraned organelles, the "powerhouses," producing ATP via cellular respiration.
- Endoplasmic Reticulum (ER):
- Rough ER: Studded with ribosomes, synthesizes and transports proteins.
- Smooth ER: Lacks ribosomes, involved in lipid synthesis and detoxification.
- Golgi Apparatus: Stacks of flattened membranes, modifying, packaging, and sorting proteins and lipids for secretion or internal use.
- Lysosomes (animal cells): Vesicles containing digestive enzymes, breaking down waste or foreign materials.
- Vacuoles: Storage sacs; large in plant cells for turgor pressure, smaller in animal cells.
- Ribosomes: Sites of protein synthesis, either free in cytoplasm or attached to rough ER.
- Cytoskeleton: Network of microtubules, microfilaments, and intermediate filaments, providing structural support and aiding movement.
- Cell Wall (plant cells): Rigid layer of cellulose outside the membrane, providing support.
- Chloroplasts (plant cells): Sites of photosynthesis, containing chlorophyll within thylakoid membranes.
Diagram Description:
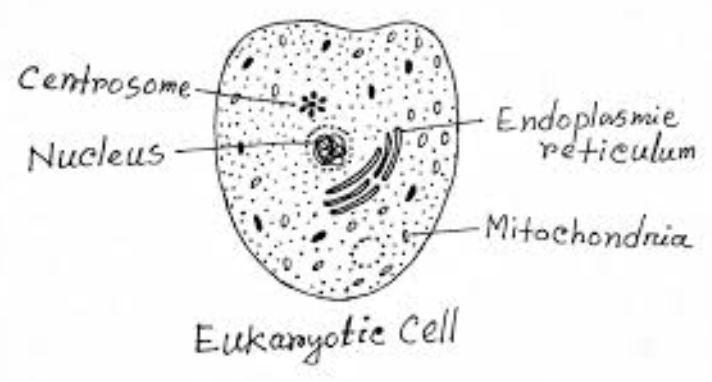
This structure enables eukaryotic cells to perform complex functions, distinguishing them from simpler prokaryotic cells.
Question:-2
Discuss ‘Operon Concept’. Describe its structure and role in gene regulation.
Answer:
1. Introduction to the Operon Concept
The operon concept, introduced by Jacob and Monod in 1961, is a fundamental model explaining coordinated gene regulation in prokaryotes, particularly bacteria like Escherichia coli. An operon is a functional unit of DNA containing a cluster of genes under the control of a single promoter, transcribed together into a single mRNA molecule. This polycistronic mRNA is then translated into multiple proteins, typically involved in a common metabolic pathway. The operon model elucidates how bacteria efficiently regulate gene expression in response to environmental changes, conserving energy by activating or repressing genes as needed. For example, the lac operon regulates lactose metabolism, activating genes only when lactose is present. This concept revolutionized molecular biology, providing insights into gene regulation mechanisms, and remains relevant for understanding prokaryotic genetics and synthetic biology applications.
2. Structure of an Operon
An operon’s structure is a well-organized DNA segment designed for coordinated gene expression. Its key components include:
- Promoter: A DNA sequence where RNA polymerase binds to initiate transcription. It is located upstream of the genes and determines the transcription start site. For instance, in the lac operon, the promoter is recognized by RNA polymerase in the presence of specific activators.
- Operator: A short DNA sequence adjacent to or overlapping the promoter, acting as a regulatory switch. Repressor proteins bind here to block transcription, while activators may enhance binding of RNA polymerase. In the lac operon, the operator binds the lac repressor to inhibit gene expression in the absence of lactose.
- Structural Genes: A set of genes encoding proteins with related functions, transcribed as a single mRNA. In the lac operon, three genes (lacZ, lacY, lacA) encode β-galactosidase, permease, and transacetylase, respectively, for lactose metabolism.
- Terminator: A sequence signaling the end of transcription, ensuring the mRNA is properly terminated.
Additional regulatory elements, like enhancers or silencers, may interact with the operon, and a regulatory gene (often outside the operon) encodes proteins controlling the operator. For example, the lacI gene produces the lac repressor in the lac operon.
3. Types of Operons
Operons are classified based on their regulatory mechanisms, reflecting diverse strategies bacteria use to adapt to environmental cues.
- Inducible Operons: These are typically “off” but activated (induced) by specific molecules. The lac operon is a classic example: in the absence of lactose, the lac repressor binds the operator, blocking transcription. When lactose is present, it binds the repressor, releasing it from the operator, allowing transcription of lactose-metabolizing genes.
- Repressible Operons: These are usually “on” but can be turned off by a corepressor. The trp operon, regulating tryptophan synthesis, exemplifies this. When tryptophan is abundant, it binds the trp repressor, which then binds the operator, halting transcription to prevent excess tryptophan production.
- Catabolite-Regulated Operons: Some operons, like the lac operon, are influenced by catabolite repression. When glucose is abundant, cyclic AMP (cAMP) levels drop, reducing the activity of the catabolite activator protein (CAP), which normally enhances lac operon transcription. This ensures bacteria prioritize glucose over lactose.
These types highlight the operon’s adaptability, enabling bacteria to fine-tune gene expression based on metabolic needs.
4. Role in Gene Regulation
The operon’s primary role is to regulate gene expression efficiently, ensuring bacteria respond swiftly to environmental changes.
- Transcriptional Control: The operator and repressor system allows precise control. In the lac operon, the repressor protein’s binding to the operator prevents unnecessary gene expression, conserving energy. Inducers or corepressors modulate this interaction, toggling genes on or off.
- Coordinated Expression: By clustering related genes, operons ensure simultaneous expression of proteins needed for a pathway. For example, the his operon in Salmonella coordinates histidine biosynthesis genes, streamlining production.
- Environmental Adaptation: Operons enable rapid responses to nutrient availability or stress. The ara operon, regulating arabinose metabolism, activates only when arabinose is present, optimizing resource use.
- Evolutionary Advantage: Operons provide a compact genetic organization, reducing the energy cost of transcription and translation, crucial for fast-growing bacteria.
5. Significance and Applications
The operon concept has profound implications in biology and biotechnology. It underpins our understanding of prokaryotic gene regulation, informing studies of bacterial adaptation, pathogenesis, and antibiotic resistance. For instance, operons controlling virulence factors in pathogens like Vibrio cholerae are critical for infection strategies. In biotechnology, operons are engineered for synthetic biology, such as designing inducible systems for protein production (e.g., using the lac operon promoter in recombinant DNA technology). The concept also aids in studying gene regulation evolution, revealing how operons emerged to optimize metabolic efficiency. Furthermore, operon-based models guide research into eukaryotic gene clusters, like Hox genes, showing broader regulatory parallels.
Conclusion
The operon concept remains a cornerstone of molecular biology, illuminating how bacteria orchestrate gene expression with remarkable precision. Its structure—promoter, operator, structural genes, and terminator—facilitates coordinated regulation, exemplified by the lac and trp operons. By enabling inducible, repressible, or catabolite-regulated responses, operons ensure bacteria adapt efficiently to environmental shifts, conserving resources and enhancing survival. Their significance extends to biotechnology, where operon-based systems drive innovations in gene expression control, and to evolutionary biology, offering insights into genetic organization. Understanding operons not only deepens our grasp of prokaryotic life but also informs broader genetic regulation principles, making it a pivotal concept in modern science.
Question:-3(a)
Describe the double helix model of DNA with a neat, well-labelled diagram.
Answer:
The Double Helix Model of DNA
The double helix model of DNA, proposed by James Watson and Francis Crick in 1953, describes the molecular structure of deoxyribonucleic acid (DNA), the hereditary material in most organisms. This model, based on X-ray diffraction data from Rosalind Franklin and Maurice Wilkins, revolutionized biology by explaining how genetic information is stored and replicated.
Structure of the Double Helix
The DNA molecule resembles a twisted ladder or spiral staircase, forming a double helix. Its key components are:
- Backbone: Two long, antiparallel sugar-phosphate chains form the "sides" of the ladder. Each chain consists of alternating deoxyribose sugar molecules and phosphate groups, linked by phosphodiester bonds. The strands run in opposite directions (5’ to 3’ and 3’ to 5’).
- Base Pairs: The "rungs" of the ladder are formed by pairs of nitrogenous bases, held together by hydrogen bonds. The bases are:
- Purines: Adenine (A) and Guanine (G).
- Pyrimidines: Thymine (T) and Cytosine (C).
Complementary base pairing occurs, with Adenine pairing with Thymine (via two hydrogen bonds) and Guanine pairing with Cytosine (via three hydrogen bonds).
- Helical Shape: The strands twist into a right-handed helix, completing a full turn approximately every 10 base pairs (about 3.4 nm). The helix has a diameter of about 2 nm, with major and minor grooves allowing proteins to access the bases for processes like transcription.
Key Features
- Antiparallel Strands: The 5’ end of one strand aligns with the 3’ end of the other, ensuring structural stability and guiding replication.
- Complementary Base Pairing: The specific A-T and G-C pairing ensures accurate replication and transcription, as each strand can serve as a template for synthesizing a new complementary strand.
- Major and Minor Grooves: The uneven spacing between the sugar-phosphate backbones creates grooves. The major groove is wider, providing binding sites for regulatory proteins.
Functional Significance
The double helix structure is critical for DNA’s roles:
- Replication: During cell division, the helix unwinds, and each strand serves as a template to synthesize a new strand, ensuring genetic continuity.
- Gene Expression: The base sequence encodes genetic information, transcribed into mRNA for protein synthesis.
- Stability: The hydrogen bonds and hydrophobic interactions between bases, along with the sturdy sugar-phosphate backbone, protect DNA from damage, ensuring long-term storage of genetic information.
Diagram
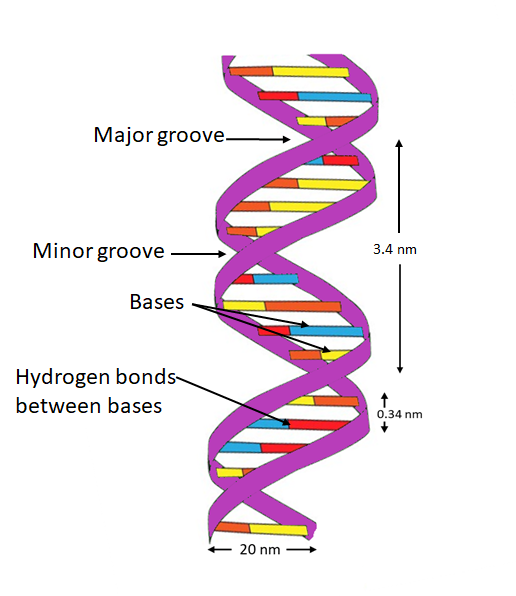
Historical Context
The Watson-Crick model built on Franklin’s X-ray images (Photo 51), which revealed the helical pattern and dimensions, and Chargaff’s rule, showing equal ratios of A-T and G-C. This model resolved how DNA replicates and transmits genetic information, earning Watson, Crick, and Wilkins the 1962 Nobel Prize in Physiology or Medicine.
In summary, the double helix model describes DNA as a stable, antiparallel, base-paired structure, elegantly suited for storing, replicating, and expressing genetic information, forming the foundation of modern genetics.
Question:-3(b)
How is the organization of DNA in prokaryotes different from that of eukaryotes? Discuss.
Answer:
1. Introduction to DNA Organization
DNA organization refers to how genetic material is structured, packaged, and stored within cells to ensure efficient storage, replication, and expression. Prokaryotes (e.g., bacteria like Escherichia coli) and eukaryotes (e.g., plants, animals, fungi) differ significantly in DNA organization due to their cellular complexity and evolutionary divergence. Prokaryotes, being simpler and unicellular, have compact, streamlined genomes, while eukaryotes, with complex, often multicellular structures, require intricate DNA packaging to fit within membrane-bound nuclei. These differences impact gene regulation, replication, and cellular function, reflecting adaptations to distinct biological needs. Understanding these distinctions is crucial for fields like molecular biology, genetics, and biotechnology.
2. DNA Structure and Location
In prokaryotes, DNA is typically a single, circular chromosome located in the cytoplasm within a region called the nucleoid, which lacks a membrane. The nucleoid is loosely organized, with DNA directly accessible for transcription and replication. For example, E. coli has one circular chromosome of about 4.6 million base pairs. Some prokaryotes, like Vibrio cholerae, may have additional smaller circular DNA molecules called plasmids, which carry non-essential genes (e.g., for antibiotic resistance).
Eukaryotes, conversely, store their DNA in a membrane-bound nucleus, organized into multiple linear chromosomes. Humans, for instance, have 46 chromosomes, each containing millions to billions of base pairs. The nuclear envelope separates DNA from cytoplasmic processes, requiring complex transport mechanisms for mRNA and proteins. Eukaryotic cells may also contain DNA in organelles like mitochondria and chloroplasts, which have circular DNA resembling prokaryotic genomes, supporting the endosymbiotic theory.
3. DNA Packaging and Compaction
Prokaryotic DNA is relatively unpackaged compared to eukaryotes, as bacteria lack extensive space constraints. The circular chromosome is supercoiled—twisted into tight loops—to fit within the cell. Proteins like HU, H-NS, and DNA gyrase assist in supercoiling and nucleoid organization, maintaining accessibility for replication and transcription. The DNA remains relatively "naked," with minimal protein association, allowing rapid gene expression in response to environmental changes, such as nutrient availability.
Eukaryotic DNA, due to its larger size and linear nature, requires extensive compaction to fit within the nucleus. DNA wraps around histone proteins, forming nucleosomes—bead-like structures where about 147 base pairs of DNA coil around a histone octamer (two copies each of H2A, H2B, H3, H4). Nucleosomes are linked by histone H1, forming a "beads-on-a-string" structure, which further coils into a 30-nm chromatin fiber. During cell division, chromatin condenses into tightly packed chromosomes visible under a microscope. This histone-based packaging not only compacts DNA but also regulates gene access, with modifications like acetylation or methylation altering chromatin structure to control transcription.
4. Genome Size and Complexity
Prokaryotic genomes are generally smaller and less complex, ranging from 0.5 to 10 million base pairs. They contain few non-coding regions, with genes densely packed and often organized into operons—clusters of genes transcribed together under a single promoter (e.g., lac operon in E. coli). Introns (non-coding sequences within genes) are rare, and most DNA is functional, minimizing wasted space. This streamlined organization supports rapid replication and adaptation in fast-dividing bacteria.
Eukaryotic genomes are significantly larger, ranging from millions to billions of base pairs (e.g., human genome: ~3 billion). They include substantial non-coding DNA, such as introns, regulatory sequences, and repetitive elements. Genes are not organized into operons but are individually regulated, with promoters and enhancers controlling transcription. Introns are spliced out post-transcription, adding complexity to gene expression. This allows eukaryotes to produce diverse proteins via alternative splicing, supporting complex multicellular functions but requiring sophisticated regulatory mechanisms.
5. Gene Regulation and Accessibility
Prokaryotic gene regulation is relatively simple, relying on operons and direct protein-DNA interactions. Transcription factors, repressors, or activators bind DNA at promoter or operator sites to control gene expression in response to environmental cues. The lack of a nucleus means transcription and translation are coupled, occurring simultaneously in the cytoplasm, enabling rapid responses (e.g., lactose metabolism activation in E. coli).
Eukaryotic gene regulation is more complex due to chromatin structure and nuclear compartmentalization. Histone modifications and DNA methylation regulate chromatin accessibility, determining whether genes are active or silenced. Transcription occurs in the nucleus, followed by mRNA processing (capping, polyadenylation, splicing) before translation in the cytoplasm. Regulatory elements like enhancers, located far from genes, interact via DNA looping, mediated by proteins like transcription factors. This multilayered regulation supports cell specialization in multicellular organisms, such as neuron-specific gene expression in humans.
Conclusion
The organization of DNA in prokaryotes and eukaryotes reflects their distinct cellular architectures and functional demands. Prokaryotes, with their single, circular chromosome in the nucleoid, prioritize simplicity and rapid gene expression through supercoiling and operon-based regulation, suited for unicellular, fast-adapting organisms. Eukaryotes, with multiple linear chromosomes in a nucleus, employ histone-based chromatin packaging, extensive non-coding DNA, and complex regulatory mechanisms to support larger genomes and multicellular complexity. These differences highlight evolutionary adaptations, with prokaryotes optimizing efficiency and eukaryotes enabling diversity and specialization. Understanding these distinctions informs genetic engineering, disease research, and evolutionary biology, bridging fundamental science with practical applications.
Question:-4(a)
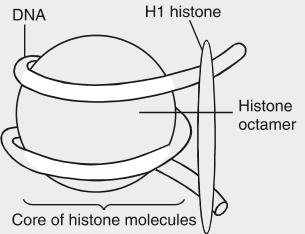
What is Nucleosome? Explain its structure with the help of a suitable diagram.
Answer:
Nucleosome: Definition and Role
A nucleosome is the fundamental unit of DNA packaging in eukaryotic cells, acting as the primary level of chromatin organization. It compacts DNA to fit within the cell nucleus while regulating access to genetic information for processes like transcription, replication, and repair. Nucleosomes enable eukaryotes to manage their large genomes efficiently, balancing storage with functionality.
Structure of a Nucleosome
The nucleosome consists of two main components: a histone protein core and the DNA wrapped around it. The detailed structure is as follows:
- Histone Core:
- The core is an octamer composed of eight histone proteins: two copies each of histones H2A, H2B, H3, and H4.
- These positively charged proteins form a cylindrical structure, stabilized by protein-protein interactions.
- Histone H1, external to the core, binds to the nucleosome and linker DNA, aiding further compaction.
- DNA Component:
- Approximately 147 base pairs (bp) of double-stranded DNA wrap around the histone octamer in about 1.65 left-handed superhelical turns.
- The DNA is negatively charged due to its phosphate backbone, facilitating electrostatic interactions with the positively charged histones.
- Adjacent nucleosomes are connected by a stretch of linker DNA, typically 20–80 bp long, forming a “beads-on-a-string” structure visible under an electron microscope.
- Additional Features:
- The histone tails, protruding from the core, are subject to post-translational modifications (e.g., acetylation, methylation), which regulate chromatin accessibility and gene expression.
- The nucleosome’s structure creates major and minor grooves in the DNA, allowing regulatory proteins to access specific DNA sequences.
Functional Significance:
- Compaction: Nucleosomes reduce DNA length, enabling meters of DNA (e.g., ~2 meters in human cells) to fit within a micrometer-sized nucleus.
- Gene Regulation: Chromatin structure modulates DNA accessibility; tightly packed nucleosomes (heterochromatin) repress transcription, while loosely packed ones (euchromatin) allow it.
- DNA Protection: The histone core shields DNA from damage, maintaining genomic integrity.
Diagram
Context and Importance
The nucleosome model was elucidated through studies by Roger Kornberg and others, building on X-ray crystallography and biochemical analyses. Nucleosomes are dynamic, undergoing remodeling by protein complexes (e.g., SWI/SNF) to facilitate DNA access during cellular processes. Their structure is critical for epigenetic regulation, as histone modifications serve as signals for gene activation or silencing, influencing development, disease (e.g., cancer), and cellular differentiation.
In summary, the nucleosome is a histone-DNA complex that compacts and organizes eukaryotic DNA while regulating gene expression. Its structure—147 bp of DNA wrapped around a histone octamer, linked by DNA, and stabilized by H1—ensures efficient genome management, making it a cornerstone of eukaryotic biology.
Question:-4(b)
Discuss the main features of the genetic code.
Answer:
1. Introduction to the Genetic Code
The genetic code is the set of rules by which the information encoded in DNA or RNA is translated into proteins, the functional molecules of life. Stored in the sequence of nucleotides, this code dictates the sequence of amino acids in polypeptides, enabling cells to synthesize proteins essential for structure, function, and regulation. Discovered through pioneering work by scientists like Marshall Nirenberg and Francis Crick in the 1960s, the genetic code is a universal blueprint across nearly all organisms, from bacteria to humans. Its main features—universality, triplet nature, degeneracy, non-overlapping structure, and unambiguous specificity—reflect its efficiency and robustness, ensuring accurate protein synthesis while allowing evolutionary flexibility. Understanding these features is critical for molecular biology, biotechnology, and medical research.
2. Universality of the Genetic Code
The genetic code is nearly universal, meaning the same codon-amino acid assignments apply across diverse organisms, from prokaryotes like Escherichia coli to eukaryotes like humans. A codon, a sequence of three nucleotides, specifies a particular amino acid or stop signal. For example, the codon AUG codes for methionine in both bacteria and mammals. This universality suggests a common evolutionary origin, supporting the idea that all life shares a single ancestor. However, minor exceptions exist, such as in mitochondrial DNA or certain protozoans (e.g., Tetrahymena), where codons like UGA code for tryptophan instead of a stop signal. These variations are rare, reinforcing the code’s near-universal consistency, which enables techniques like recombinant DNA technology, where bacterial cells produce human proteins (e.g., insulin).
3. Triplet Nature of the Code
The genetic code operates in triplets, with each codon consisting of three nucleotides. The four nucleotide bases (adenine, cytosine, guanine, uracil in RNA or thymine in DNA) yield 64 possible codons (4³), sufficient to encode the 20 standard amino acids and three stop signals. For instance, the codon GCA codes for alanine, while UAA signals translation termination. The triplet structure ensures precision in reading the genetic sequence, as each codon corresponds to a single amino acid or instruction. Experiments by Nirenberg and Matthaei, using synthetic RNA, confirmed that triplets, not doublets or single nucleotides, are the functional units, balancing complexity and efficiency in protein synthesis.
4. Degeneracy of the Code
Degeneracy, or redundancy, is a hallmark of the genetic code, where multiple codons encode the same amino acid. Of the 64 codons, 61 code for amino acids, and three are stop codons (UAA, UAG, UGA). Most amino acids are specified by more than one codon; for example, leucine is encoded by six codons (UUA, UUG, CUU, CUC, CUA, CUG). This redundancy reduces the impact of mutations, as a change in the third nucleotide (the “wobble” position) often does not alter the amino acid (e.g., GGU, GGC, GGA, GGG all code for glycine). Degeneracy enhances genetic stability, allowing organisms to tolerate minor errors in DNA replication or transcription without disrupting protein function.
5. Non-Overlapping and Unambiguous Nature
The genetic code is non-overlapping, meaning each nucleotide belongs to only one codon, and the reading frame is fixed. Translation reads codons sequentially without skipping or reusing nucleotides. For example, in the sequence AUGCCUGAA, AUG codes for methionine, CCU for proline, and GAA for glutamic acid, with no overlap. This ensures clarity in translation. Additionally, the code is unambiguous: each codon specifies only one amino acid or stop signal. For instance, AUG always codes for methionine (or serves as a start codon), eliminating confusion during protein synthesis. This precision is critical for producing functional proteins with correct amino acid sequences.
6. Start and Stop Codons
The genetic code includes specific codons to initiate and terminate translation. The start codon, AUG, codes for methionine and signals the beginning of protein synthesis in both prokaryotes and eukaryotes. In bacteria, AUG is part of a larger initiation complex involving the Shine-Dalgarno sequence. Stop codons—UAA, UAG, and UGA—signal the end of translation, prompting the release of the polypeptide from the ribosome. These codons do not code for amino acids but are recognized by release factors that disassemble the translation machinery. The presence of start and stop codons ensures that proteins are synthesized with defined boundaries, critical for their structure and function.
Conclusion
The genetic code’s main features—universality, triplet structure, degeneracy, non-overlapping and unambiguous nature, and defined start/stop codons—underpin its role as the universal language of life. Its near-universal application across species highlights a shared evolutionary heritage, while its triplet and degenerate properties balance efficiency and error tolerance. The non-overlapping, unambiguous structure ensures precise translation, and start/stop codons provide clear instructions for protein synthesis. These characteristics make the genetic code robust yet flexible, supporting life’s diversity and enabling biotechnological advances like gene editing and synthetic biology. By decoding the rules governing protein synthesis, the genetic code remains a cornerstone of biology, driving research into heredity, disease, and evolution.
Question:-5(a)
Enlist the major differences between plant and animal cells.
Answer:
1. Introduction to Plant and Animal Cells
Plant and animal cells are eukaryotic, sharing core features like a nucleus, membrane-bound organelles, and a cytoskeleton. However, their distinct evolutionary paths and functional roles—plants as autotrophic producers and animals as heterotrophic consumers—result in structural and functional differences. These adaptations reflect plants’ need for photosynthesis and structural rigidity versus animals’ requirements for mobility and diverse tissue functions. Understanding these differences is fundamental to biology, illuminating cellular specialization and organismal diversity. Key distinctions include cell walls, plastids, vacuoles, centrioles, and energy storage mechanisms.
2. Cell Wall Presence and Composition
Plant cells possess a rigid cell wall external to the plasma membrane, primarily composed of cellulose, hemicellulose, and pectin. This wall provides structural support, maintains cell shape, and protects against mechanical stress and pathogens. For example, the cell wall enables trees to grow tall and withstand wind. Animal cells lack a cell wall, having only a flexible plasma membrane. This absence allows animal cells to adopt varied shapes and facilitates movement, as seen in muscle cells or amoeboid motion in white blood cells. The lack of a cell wall makes animal cells more susceptible to osmotic lysis, requiring precise osmotic regulation.
3. Plastids and Photosynthetic Capability
Plant cells contain plastids, specialized organelles critical for photosynthesis and storage. Chloroplasts, a type of plastid, house chlorophyll, enabling plants to convert sunlight into energy, as in leaf cells of spinach. Other plastids, like amyloplasts, store starch in roots (e.g., potatoes). Animal cells lack plastids entirely, as they rely on consuming organic compounds for energy. This fundamental difference underscores plants’ autotrophic nature versus animals’ heterotrophic dependence, with animal cells obtaining energy through mitochondria alone, metabolizing glucose from ingested food (e.g., liver cells processing dietary sugars).
4. Vacuole Size and Function
Plant cells typically have a large central vacuole, occupying up to 90% of the cell volume. This vacuole stores water, nutrients, and waste, maintains turgor pressure for structural support, and aids in cell expansion, as seen in succulent plants. It also degrades cellular waste, acting like a lysosome. Animal cells have small, numerous vacuoles (if present), primarily for temporary storage or transport, as in kidney cells handling waste. The large central vacuole’s role in plants contrasts with animal cells’ reliance on lysosomes for digestion and smaller vacuoles for minor storage, reflecting different cellular priorities.
5. Centrioles and Cell Division
Animal cells contain centrioles, paired cylindrical structures organizing microtubules during cell division (mitosis). Centrioles form the spindle apparatus, ensuring accurate chromosome segregation, as in human skin cells. Plant cells lack centrioles, relying on alternative microtubule-organizing centers for spindle formation during mitosis, as in onion root tip cells. This difference reflects plants’ rigid cell walls, which constrain cell movement and division mechanics, versus animals’ flexible cells, where centrioles facilitate precise cytoskeletal dynamics. While centrioles are absent in plants, both cell types achieve effective division, adapted to their structural contexts.
6. Energy Storage Molecules
Plant cells store energy primarily as starch, a polysaccharide accumulated in plastids like amyloplasts (e.g., in rice grains). Starch provides a stable, long-term energy reserve for growth and reproduction. Animal cells store energy as glycogen, a branched polysaccharide stored in the cytoplasm, particularly in liver and muscle cells. Glycogen is rapidly mobilized for energy during activity, reflecting animals’ need for quick energy access. This distinction highlights plants’ focus on sustained energy storage versus animals’ emphasis on immediate energy availability, aligning with their respective lifestyles.
Conclusion
The major differences between plant and animal cells—cell walls, plastids, vacuole size, centrioles, and energy storage—reflect their specialized roles in organismal biology. Plant cells’ rigid walls and chloroplasts support photosynthesis and structural integrity, while large vacuoles maintain turgor. Animal cells’ flexibility, centrioles, and glycogen storage enable mobility and rapid energy use. These adaptations underscore the evolutionary divergence between autotrophic plants and heterotrophic animals, shaping their cellular structures to meet distinct environmental and functional demands. Understanding these differences enhances insights into cellular biology, informing applications in agriculture, medicine, and biotechnology.
Question:-5(b)
Explain Chargaff’s Rule.
Answer:
Chargaff’s Rule
Chargaff’s Rule, named after biochemist Erwin Chargaff, is a fundamental principle in molecular biology that describes the consistent ratios of nucleotide bases in DNA. Based on Chargaff’s biochemical analyses in the 1940s, the rule states that in double-stranded DNA, the amount of adenine (A) is equal to the amount of thymine (T), and the amount of guanine (G) is equal to the amount of cytosine (C). This is expressed as:
- A = T and G = C
Additionally, the total amount of purines (A + G) equals the total amount of pyrimidines (T + C).
Explanation
The rule arises from the structure of DNA’s double helix, where bases pair specifically: adenine pairs with thymine via two hydrogen bonds, and guanine pairs with cytosine via three hydrogen bonds. This complementary base pairing ensures that for every A on one strand, there is a T on the complementary strand, and for every G, there is a C. Chargaff’s experiments, involving hydrolysis and chromatography of DNA from various organisms (e.g., bacteria, humans), revealed these consistent ratios, despite variations in overall base composition across species. For example, human DNA might have 30% A, 30% T, 20% G, and 20% C, adhering to the rule.
Significance
- Foundation for DNA Structure: Chargaff’s Rule provided critical evidence for Watson and Crick’s double helix model in 1953, confirming that base pairing underpins DNA’s structure.
- Replication and Transcription: The rule ensures accurate DNA replication, as each strand serves as a template to synthesize a complementary strand with matching base ratios.
- Evolutionary Insights: Variations in A+T versus G+C content across species (while maintaining A=T and G=C) reflect evolutionary adaptations, useful in taxonomy and genomics.
Exceptions
Chargaff’s Rule applies strictly to double-stranded DNA. In single-stranded DNA (e.g., some viruses) or RNA, base ratios may not follow this pattern due to the absence of complementary pairing. Mitochondrial DNA also shows slight deviations due to its unique evolutionary history.
Conclusion
Chargaff’s Rule highlights the precise, complementary nature of DNA’s base pairing, a cornerstone of its structure and function. By establishing that A equals T and G equals C, it paved the way for understanding DNA’s double helix, replication, and genetic coding, remaining a pivotal concept in biology.
Question:-6
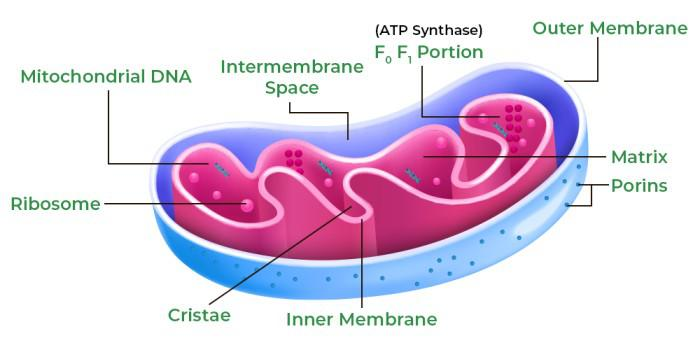
Describe the structure, composition and functions of mitochondria along with a well-labelled diagram.
Answer:
Mitochondria: Structure, Composition, and Functions
Mitochondria are double-membraned organelles found in most eukaryotic cells, often referred to as the "powerhouses" due to their role in energy production. They are critical for cellular metabolism, playing key roles in ATP synthesis, metabolic regulation, and other cellular processes. Below is a detailed description of their structure, composition, and functions, accompanied by a textual description of a labeled diagram.
Structure of Mitochondria
Mitochondria are typically rod-shaped or oval, ranging from 0.5 to 10 micrometers in length, though their shape and number vary based on cell type and energy demands (e.g., abundant in muscle cells). Their structure consists of:
- Outer Membrane:
- A smooth, porous membrane composed of a phospholipid bilayer with proteins (e.g., porins).
- Allows passage of small molecules (<5,000 Da) like ions and sugars, creating an intermembrane space.
- Intermembrane Space:
- The compartment between the outer and inner membranes, containing enzymes involved in metabolic reactions and ions that support the proton gradient for ATP synthesis.
- Inner Membrane:
- A highly folded membrane forming cristae, increasing surface area for energy production.
- Contains the electron transport chain (ETC) proteins, ATP synthase, and transport proteins.
- Less permeable, tightly regulating molecule passage.
- Cristae:
- Folds of the inner membrane, maximizing space for oxidative phosphorylation.
- Host ETC complexes and ATP synthase, critical for ATP generation.
- Matrix:
- The innermost compartment, enclosed by the inner membrane.
- A gel-like region containing enzymes, mitochondrial DNA (mtDNA), ribosomes, and tRNAs.
Composition of Mitochondria
Mitochondria are composed of lipids, proteins, nucleic acids, and other molecules, organized to support their functions:
- Lipids:
- The outer and inner membranes are phospholipid bilayers, with cardiolipin (unique to the inner membrane) enhancing membrane stability and ETC function.
- Proteins:
- Over 1,000 proteins, including:
- ETC Complexes: Complexes I–IV in the inner membrane for electron transport.
- ATP Synthase: A rotary enzyme in cristae synthesizing ATP.
- Enzymes: Matrix enzymes (e.g., citrate synthase) for the citric acid cycle (Krebs cycle).
- Transport Proteins: Facilitate molecule exchange across membranes.
- Over 1,000 proteins, including:
- Nucleic Acids:
- Mitochondrial DNA (mtDNA), a circular, double-stranded molecule (~16.5 kb in humans), encoding 13 proteins, 22 tRNAs, and 2 rRNAs for mitochondrial protein synthesis.
- Mitochondrial ribosomes (70S, prokaryote-like) translate mtDNA-encoded genes.
- Other Components:
- Coenzymes (e.g., NADH, FADH₂), ions (e.g., calcium), and metabolites support metabolic reactions.
Functions of Mitochondria
Mitochondria perform multiple essential functions beyond energy production:
- ATP Synthesis (Cellular Respiration):
- Mitochondria generate ATP via oxidative phosphorylation. The Krebs cycle in the matrix produces NADH and FADH₂, which donate electrons to the ETC in the inner membrane. Electron movement creates a proton gradient across the inner membrane, driving ATP synthase to produce ATP from ADP and phosphate. This process yields ~30–32 ATP per glucose molecule.
- Metabolic Regulation:
- Mitochondria host the Krebs cycle, linking carbohydrate, fat, and protein metabolism. They oxidize pyruvate, fatty acids, and amino acids, integrating nutrient breakdown (e.g., fatty acid β-oxidation in liver cells).
- Calcium Homeostasis:
- Mitochondria regulate cellular calcium levels by uptake and release, influencing signaling pathways and processes like muscle contraction and neurotransmitter release.
- Apoptosis (Programmed Cell Death):
- Mitochondria release cytochrome c from the intermembrane space, triggering apoptosis to eliminate damaged cells, critical in development and cancer prevention.
- Heat Production:
- In brown adipose tissue, mitochondria uncouple proton movement from ATP synthesis, generating heat via thermogenesis (e.g., in hibernating animals).
- Biosynthesis:
- Mitochondria contribute to heme and steroid synthesis, with enzymes in the matrix and inner membrane supporting these pathways.
Diagram
Significance
Mitochondria’s prokaryote-like features (circular DNA, 70S ribosomes) support the endosymbiotic theory, suggesting they evolved from engulfed bacteria. Their dysfunction is linked to diseases like mitochondrial myopathies, neurodegenerative disorders, and aging, highlighting their critical role in cellular health.
In summary, mitochondria are dynamic organelles with a double-membraned structure, lipid-protein composition, and diverse functions, primarily ATP production, but also metabolic integration, calcium signaling, and apoptosis. Their organization optimizes energy efficiency, making them indispensable to eukaryotic life.
Question:-7
Describe Griffith’s experiment for the demonstration of DNA as a genetic material with a properly labelled diagram.
Answer:
1. Introduction to Griffith’s Experiment
Frederick Griffith’s 1928 experiment was a pivotal milestone in molecular biology, providing the first evidence that a “transforming principle,” later identified as DNA, could transfer genetic traits between bacterial cells. Conducted using Streptococcus pneumoniae (pneumococcus), Griffith’s work aimed to understand bacterial virulence and its implications for pneumonia vaccines. His unexpected discovery of transformation—the process by which a non-virulent bacterial strain acquired virulence from a dead virulent strain—laid the groundwork for identifying DNA as the genetic material. This experiment shifted scientific focus from proteins to nucleic acids as carriers of heredity, influencing subsequent research by Avery, MacLeod, McCarty, and others. Its significance lies in demonstrating that genetic information is transferable, a cornerstone of modern genetics.
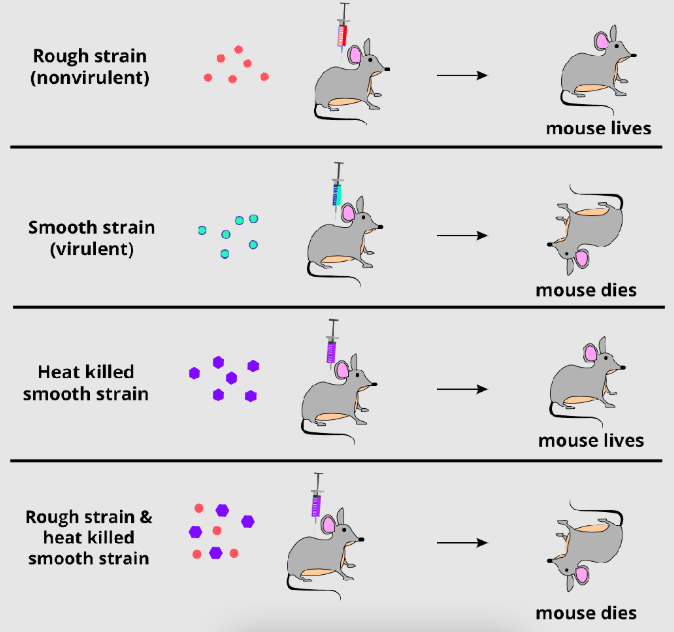
2. Experimental Setup and Materials
Griffith used two strains of Streptococcus pneumoniae, distinguished by their virulence and colony appearance:
- Smooth (S) Strain: Virulent, encapsulated with a polysaccharide coat, causing fatal pneumonia in mice. The capsule gives colonies a smooth appearance and protects bacteria from the host immune system.
- Rough (R) Strain: Non-virulent, lacking the polysaccharide capsule, resulting in rough-edged colonies. This strain does not cause disease, as it is easily destroyed by the immune system.
The bacteria were cultured and manipulated under controlled conditions. Griffith injected mice with various combinations of live and heat-killed bacteria to observe their effects. Heat-killing the S strain destroyed its ability to cause disease but preserved its chemical components. The experiment involved intraperitoneal injections into mice, followed by monitoring for survival and analyzing bacterial presence in their blood.
3. Key Experimental Steps
Griffith’s experiment consisted of four distinct tests, each designed to probe the interaction between bacterial strains and their impact on virulence:
- Injection of Live S Strain: Mice injected with live S strain bacteria developed pneumonia and died within days. Blood samples revealed abundant S strain bacteria, confirming their virulence.
- Injection of Live R Strain: Mice injected with live R strain survived, showing no signs of disease. Blood cultures confirmed the presence of R strain bacteria, verifying their non-virulence.
- Injection of Heat-Killed S Strain: Mice injected with heat-killed S strain also survived, as the heat treatment destroyed the bacteria’s ability to infect. No viable bacteria were recovered from the blood, indicating that dead S strain alone was harmless.
- Injection of Heat-Killed S Strain + Live R Strain: In the critical test, mice received a mixture of heat-killed S strain and live R strain. Surprisingly, many mice developed pneumonia and died. Blood analysis revealed live S strain bacteria with polysaccharide capsules, despite only heat-killed S strain being administered.
This final result suggested that some component of the dead S strain transformed the non-virulent R strain into a virulent S strain, a phenomenon Griffith termed “transformation.”
4. Observations and Interpretation
The unexpected outcome of the mixed injection was the cornerstone of Griffith’s findings. The presence of live S strain bacteria in the blood of dead mice indicated that the R strain had acquired the ability to produce the polysaccharide capsule, a trait characteristic of the S strain. Griffith hypothesized that a “transforming principle” from the heat-killed S strain was responsible for this change. This principle was stable, as it survived heat treatment, and heritable, as transformed R bacteria passed the virulent trait to their progeny. Griffith initially speculated that the transforming principle might be a chemical substance but did not identify it as DNA, as proteins were then considered the likely genetic material.
The transformation process implied that genetic information could be transferred between cells, challenging existing views on heredity. The polysaccharide capsule itself was not the transforming agent, as it is not genetic material; rather, the genes encoding its synthesis were transferred, enabling R bacteria to produce the capsule and become virulent.
5. Significance and Limitations
Griffith’s experiment was groundbreaking for several reasons. It provided the first evidence of genetic transformation, suggesting that a chemical substance could carry hereditary information. This finding inspired later experiments, notably by Avery, MacLeod, and McCarty in 1944, who identified DNA as the transforming principle. Griffith’s work also had practical implications, advancing understanding of bacterial pathogenesis and vaccine development for pneumonia.
However, the experiment had limitations. Griffith did not pinpoint DNA as the transforming principle, as the role of nucleic acids in heredity was not widely accepted. His focus was on bacterial virulence, not the nature of genetic material. Additionally, the experiment lacked molecular techniques to isolate and analyze the transforming substance, leaving the mechanism of transformation unclear. Subsequent studies using enzymatic degradation (e.g., DNase destroying transformation) clarified DNA’s role.
Conclusion
Griffith’s 1928 experiment was a seminal contribution to genetics, demonstrating that a transforming principle, later confirmed as DNA, could transfer genetic traits between bacteria. By showing that non-virulent R strain Streptococcus pneumoniae could acquire virulence from heat-killed S strain, Griffith revealed the phenomenon of transformation, challenging protein-centric views of heredity. His meticulous setup, involving live and heat-killed bacterial strains and mouse models, provided compelling evidence of genetic transfer, despite not identifying DNA directly. The experiment’s legacy lies in its role as a catalyst for identifying DNA as the genetic material, shaping modern molecular biology. Its insights into bacterial transformation continue to influence genetic engineering, biotechnology, and our understanding of heredity, underscoring the power of unexpected discoveries in science.
Question:-8
Describe various stages of Meiosis I with the help of a well-labelled diagram.
Answer:
1. Introduction to Meiosis I
Meiosis is a specialized cell division process in sexually reproducing organisms, producing gametes (sperm and eggs) with half the chromosome number (haploid) of the parent cell (diploid). Meiosis I, the first of two divisions, is critical for reducing chromosome number and promoting genetic diversity through recombination and independent assortment. It consists of four stages—prophase I, metaphase I, anaphase I, and telophase I—followed by cytokinesis. These stages ensure precise chromosome segregation and genetic variation, essential for evolution and reproduction. Understanding Meiosis I is fundamental to genetics, as errors can lead to conditions like Down syndrome.
2. Prophase I
Prophase I is the longest and most complex stage, marked by chromosome condensation and genetic recombination. The nuclear envelope begins to break down, and the nucleolus disappears. Homologous chromosomes (one from each parent) pair up in a process called synapsis, forming tetrads (four chromatids). Within tetrads, crossing over occurs, where non-sister chromatids exchange genetic material at chiasmata, increasing genetic diversity. For example, in human cells, multiple crossovers per chromosome pair shuffle alleles, creating unique gametes. The spindle apparatus, composed of microtubules, starts forming, and centrosomes (with centrioles in animal cells) move to opposite poles. By the end, chromosomes are visible as distinct, condensed structures under a microscope, setting the stage for alignment.
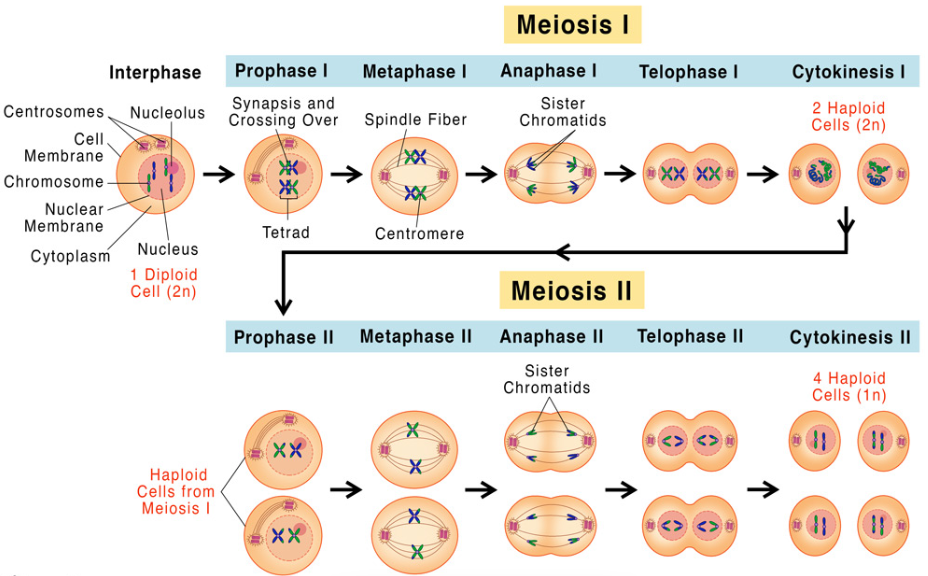
3. Metaphase I
In metaphase I, the spindle apparatus is fully formed, and homologous chromosome pairs (tetrads) align at the metaphase plate, the cell’s equatorial plane. Unlike mitosis, where individual chromosomes align, tetrads are positioned with homologous pairs facing opposite poles. This alignment is random, contributing to independent assortment, where maternal and paternal chromosomes segregate independently, generating genetic variation. For instance, in humans with 23 chromosome pairs, this randomness produces 2²³ (over 8 million) possible gamete combinations. Spindle microtubules attach to kinetochores (protein structures on centromeres) of each chromosome, ensuring proper segregation. The cell prepares for chromosome separation, with tension from microtubules stabilizing the alignment.
4. Anaphase I
Anaphase I involves the separation of homologous chromosomes, reducing the chromosome number from diploid to haploid. Spindle microtubules shorten, pulling homologous chromosomes apart toward opposite poles. Unlike mitosis, sister chromatids remain attached at their centromeres, and each pole receives one chromosome from each homologous pair. This disjunction is critical for halving the genetic material; for example, a human cell with 46 chromosomes (23 pairs) segregates to form two cells, each with 23 chromosomes (each with two sister chromatids). Chiasmata from crossing over resolve, ensuring smooth separation. Errors in anaphase I, such as nondisjunction, can result in gametes with abnormal chromosome numbers, leading to disorders like trisomy.
5. Telophase I and Cytokinesis
In telophase I, separated homologous chromosomes reach opposite poles, and the cell prepares to divide. Chromosomes may partially decondense, and in some organisms, a nuclear envelope reforms around each chromosome set, though this varies (e.g., absent in some plants). The spindle apparatus disassembles, and cytokinesis, the division of cytoplasm, occurs, typically via a cleavage furrow in animal cells or a cell plate in plant cells. This results in two daughter cells, each haploid but with chromosomes consisting of two sister chromatids. For example, in a human cell, each daughter cell has 23 chromosomes, ready for Meiosis II to separate sister chromatids. Telophase I marks the completion of the reductional division, setting up the second meiotic division.
Conclusion
Meiosis I is a meticulously orchestrated process that halves the chromosome number and enhances genetic diversity through its four stages: prophase I, metaphase I, anaphase I, and telophase I, followed by cytokinesis. Prophase I facilitates recombination via crossing over, metaphase I ensures random chromosome alignment, anaphase I achieves chromosome reduction, and telophase I prepares cells for further division. These stages collectively produce haploid cells with unique genetic combinations, crucial for sexual reproduction and evolutionary adaptability. The precision of Meiosis I underpins genetic stability, and its study illuminates mechanisms of heredity, development, and genetic disorders, advancing fields like reproductive biology and medicine.
Question:-9
List various models proposed for the structure of cell membranes. Explain the ‘Fluid Mosaic Model’ with the help of a well-labelled diagram.
Answer:
List of Various Models Proposed for the Structure of Cell Membranes
Several models have been proposed to explain the structure of cell membranes, reflecting evolving scientific understanding of their composition and function. These include:
- Lipid Monolayer Model (Early 1900s):
- Proposed by researchers like Irving Langmuir, this model suggested that cell membranes consist of a single layer of lipids, with hydrophilic heads facing the aqueous environment and hydrophobic tails inward. It was based on early lipid studies but failed to account for membrane thickness and protein presence.
- Lipid Bilayer Model (1925):
- Gorter and Grendel hypothesized that membranes are composed of a double layer of lipids, with hydrophilic heads facing outward toward the aqueous cytoplasm and extracellular environment, and hydrophobic tails inward. This model explained membrane thickness but overlooked proteins’ role.
- Davson-Danielli Model (1935):
- Also called the “protein-lipid sandwich model,” James Davson and Hugh Danielli proposed a lipid bilayer coated on both sides by layers of proteins. The model accounted for proteins but incorrectly assumed they formed continuous sheets, limiting membrane fluidity.
- Unit Membrane Model (1959):
- J. David Robertson refined the Davson-Danielli model, suggesting a uniform lipid bilayer with proteins embedded or attached to its surfaces, based on electron microscopy. It still overestimated protein rigidity and underestimated membrane dynamics.
- Fluid Mosaic Model (1972):
- Proposed by S.J. Singer and Garth Nicolson, this widely accepted model describes the cell membrane as a dynamic, fluid lipid bilayer with embedded and surface proteins, resembling a mosaic. It accounts for membrane fluidity, protein diversity, and functional flexibility.
Explanation of the Fluid Mosaic Model
The Fluid Mosaic Model, introduced by S.J. Singer and Garth Nicolson in 1972, is the cornerstone of modern understanding of cell membrane structure. It describes the plasma membrane as a dynamic, flexible structure composed of a lipid bilayer with proteins embedded or attached, resembling a mosaic pattern. This model integrates biochemical, biophysical, and electron microscopy data, addressing limitations of earlier models by emphasizing fluidity and functional diversity.
Structure of the Fluid Mosaic Model
- Lipid Bilayer:
- The backbone of the membrane is a double layer of phospholipids, each with a hydrophilic (water-attracting) head and two hydrophobic (water-repelling) tails.
- The phospholipids arrange with heads facing the aqueous extracellular and cytoplasmic environments and tails forming a hydrophobic core, creating a semi-permeable barrier.
- Other lipids, like cholesterol (in animal cells), modulate fluidity and stability, preventing excessive rigidity or fluidity.
- Proteins:
- Proteins are dispersed within or on the lipid bilayer, contributing to the “mosaic” appearance.
- Integral Proteins: Embedded in the bilayer, often spanning both layers (transmembrane proteins), they function as channels (e.g., ion channels), transporters (e.g., glucose transporters), or receptors (e.g., insulin receptors).
- Peripheral Proteins: Attached to the inner or outer surface, they support structural integrity or signaling (e.g., cytoskeletal anchors).
- Glycoproteins: Proteins with attached carbohydrates, involved in cell recognition and adhesion (e.g., blood group antigens).
- Fluidity:
- The lipid bilayer is fluid, with phospholipids and proteins able to move laterally within their layer, like molecules in a liquid. This fluidity allows membrane flexibility, self-healing, and dynamic processes like vesicle formation.
- Factors like temperature, cholesterol content, and fatty acid saturation influence fluidity. Unsaturated fatty acids increase fluidity due to kinks in their tails, while cholesterol buffers fluidity changes.
Functional Significance
- Selective Permeability: The hydrophobic core restricts polar molecule passage, while proteins facilitate selective transport (e.g., sodium-potassium pump).
- Cell Signaling: Receptors detect external signals (e.g., hormones), triggering intracellular responses.
- Cell Adhesion and Recognition: Glycoproteins mediate cell-cell interactions, critical in immune responses and tissue formation.
- Dynamic Processes: Fluidity enables membrane remodeling during endocytosis, exocytosis, and cell division.
Supporting Evidence
The Fluid Mosaic Model was supported by experiments like:
- Freeze-Fracture Electron Microscopy: Revealed proteins embedded in the lipid bilayer.
- Fluorescence Recovery After Photobleaching (FRAP): Demonstrated lateral movement of lipids and proteins.
- Lipid Asymmetry Studies: Confirmed varied lipid compositions in inner and outer leaflets, supporting functional specialization.
Diagram
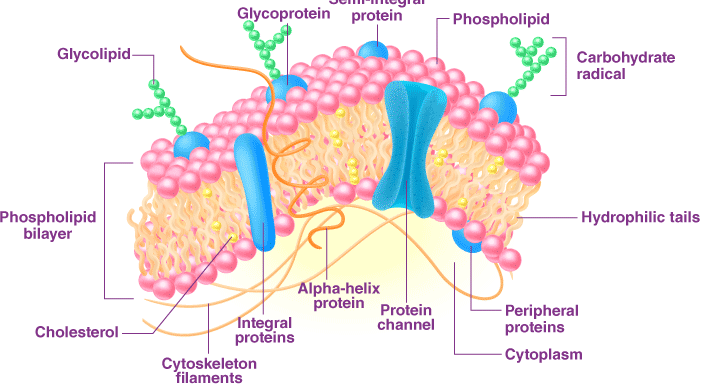
Conclusion
The Fluid Mosaic Model revolutionized membrane biology by depicting the cell membrane as a dynamic, fluid lipid bilayer with embedded proteins, overcoming the static views of earlier models. Its emphasis on fluidity, protein diversity, and functional flexibility explains the membrane’s roles in transport, signaling, and cell interactions, making it a foundational concept in cell biology.
Question:-10(a)
Write short note on Golgi apparatus.
Answer:
Golgi Apparatus
The Golgi apparatus, also known as the Golgi complex or Golgi body, is a membrane-bound organelle found in eukaryotic cells, named after its discoverer, Camillo Golgi. It plays a central role in the processing, modification, and sorting of proteins and lipids synthesized in the endoplasmic reticulum (ER).
Structure: The Golgi apparatus consists of a series of flattened, stacked membrane-bound sacs called cisternae, typically 5–8 per stack, forming a curved, ribbon-like structure near the nucleus. It has three regions: the cis-Golgi (closest to the ER, receiving vesicles), the medial-Golgi (intermediate processing), and the trans-Golgi (sorting and dispatching). Vesicles shuttle materials to and from the Golgi.
Composition: Composed of phospholipid bilayers, the cisternae contain enzymes (e.g., glycosyltransferases), proteins, and lipids. Each cisterna has specific enzymes for sequential modifications.
Functions:
- Protein Modification: Adds carbohydrates (glycosylation) or phosphates to proteins, refining their structure (e.g., forming glycoproteins for cell membranes).
- Lipid Processing: Modifies lipids, including synthesizing glycolipids and sphingomyelin.
- Sorting and Packaging: Sorts molecules into vesicles for secretion, lysosomal delivery, or membrane integration (e.g., insulin secretion in pancreatic cells).
- Lysosome Formation: Produces lysosomes by packaging hydrolytic enzymes.
Significance: Essential for cell communication, secretion, and maintaining membrane integrity, its dysfunction is linked to diseases like Alzheimer’s and congenital disorders.
In summary, the Golgi apparatus is a dynamic organelle critical for processing and dispatching cellular products, ensuring proper cellular function and organismal health.
Question:-10(b)
Write short note on Function of the cell wall in plants.
Answer:
Function of the Cell Wall in Plants
The cell wall is a rigid, protective layer surrounding the plasma membrane in plant cells, primarily composed of cellulose, hemicellulose, pectin, and sometimes lignin. It plays critical roles in plant structure, growth, and survival, distinguishing plant cells from animal cells.
- Structural Support: The cell wall provides mechanical strength and rigidity, maintaining cell shape and preventing bursting under turgor pressure. It enables plants to grow upright, as seen in tall trees like oaks, and supports tissues against environmental stresses like wind.
- Protection: It acts as a physical barrier, shielding cells from pathogens (e.g., fungi), mechanical damage, and dehydration. For instance, the waxy cuticle on epidermal cell walls reduces water loss.
- Regulation of Growth: The wall’s flexibility allows controlled cell expansion during growth, guided by turgor pressure and enzymes that modify wall components (e.g., expansins in growing stems).
- Transport and Communication: Pores called plasmodesmata in the cell wall facilitate intercellular transport of nutrients and signaling molecules, coordinating plant responses (e.g., in root cells).
- Defense and Storage: Secondary cell walls, rich in lignin, enhance defense (e.g., in xylem), while some walls store carbohydrates (e.g., pectin in fruit cells).
In summary, the plant cell wall is essential for structural integrity, protection, growth regulation, and intercellular communication, underpinning plant resilience and development.
Question:-10(c)
Write short note on Cloverleaf model of t-RNA.
Answer:
Cloverleaf Model of tRNA
The cloverleaf model describes the two-dimensional secondary structure of transfer RNA (tRNA), a crucial molecule in protein synthesis that transports amino acids to ribosomes. Proposed by Robert Holley in 1965 after sequencing alanine tRNA, this model illustrates tRNA’s folded RNA chain, resembling a cloverleaf, which facilitates its function in translating mRNA codons into proteins.
Structure:
- tRNA is a single-stranded RNA molecule (~76–90 nucleotides) folding into a cloverleaf shape via intramolecular base pairing.
- Acceptor Stem: Formed by 7–9 base pairs at the 3’ and 5’ ends, where the 3’ end has a CCA sequence that binds a specific amino acid (e.g., alanine in alanyl-tRNA).
- D Arm: Contains dihydrouridine (D) bases, with a stem (4–6 base pairs) and loop, aiding in tRNA stability and recognition by aminoacyl-tRNA synthetase.
- Anticodon Arm: A 5-base-pair stem and a loop with the anticodon (3 nucleotides), which pairs with the mRNA codon (e.g., anticodon UAC pairs with AUG for methionine).
- T Arm: Contains thymine and pseudouridine (ψ), with a stem and loop, interacting with ribosomes during translation.
- Variable Loop: Varies in size, contributing to tRNA specificity.
Function:
- The cloverleaf structure positions the anticodon to read mRNA codons accurately and the acceptor stem to carry the correct amino acid, ensuring precise protein synthesis.
- Its compact shape allows recognition by enzymes and ribosomal sites.
Significance:
The model, confirmed by X-ray crystallography, reveals tRNA’s functional design. Its L-shaped tertiary structure (folded cloverleaf) underpins translation accuracy, critical for cellular function and genetic expression.
The model, confirmed by X-ray crystallography, reveals tRNA’s functional design. Its L-shaped tertiary structure (folded cloverleaf) underpins translation accuracy, critical for cellular function and genetic expression.
In summary, the cloverleaf model of tRNA illustrates its structured RNA folding, enabling amino acid delivery and codon recognition, a cornerstone of molecular biology.
Question:-10(d)
Write short note on Enzyme telomerase.
Answer:
Enzyme Telomerase
Telomerase is a specialized ribonucleoprotein enzyme critical for maintaining telomere length in eukaryotic cells, ensuring genomic stability during cell division. Discovered by Elizabeth Blackburn and Carol Greider in 1985, it plays a vital role in counteracting the shortening of chromosome ends, which occurs naturally during DNA replication.
Structure:
- Telomerase is composed of two main components:
- TERT (Telomerase Reverse Transcriptase): The catalytic protein subunit that adds nucleotides to chromosome ends.
- TERC (Telomerase RNA Component): An RNA template that provides the sequence for telomere synthesis.
- Additional proteins (e.g., dyskerin) stabilize the complex and regulate its activity.
Function:
- Telomeres, repetitive DNA sequences (e.g., TTAGGG in humans) at chromosome ends, protect chromosomes from degradation and fusion. During DNA replication, the “end-replication problem” leaves telomeres incomplete, causing progressive shortening.
- Telomerase extends telomeres by using its RNA template to add repetitive nucleotide sequences to the 3’ end of chromosomes, compensating for this loss.
- It is highly active in stem cells, germ cells, and cancer cells, maintaining their proliferative capacity, but is typically inactive in most somatic cells, limiting their lifespan.
Significance:
- Aging and Disease: Telomerase inactivity in somatic cells leads to telomere shortening, contributing to aging and age-related diseases. Mutations in telomerase genes cause disorders like dyskeratosis congenita.
- Cancer: Overactive telomerase in cancer cells enables unlimited cell division, making it a target for therapies.
- Biotechnology: Telomerase manipulation is explored for regenerative medicine and anti-aging research.
In summary, telomerase is a crucial enzyme that maintains telomere length, supporting cell division and genomic integrity. Its role in aging, cancer, and stem cell function underscores its importance in biology and medicine.